
Ảo tưởng Tư duy — AI Reasoning hay gimmick
I/ Chuyện gì đang xảy ra?

Tuần này, Apple thả quả 1 quả bom làm dân tình xôn xao, tựa đề nghe đã thấy “ngầu”: “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity”. Đại khái, bọn họ lấy mấy trò chơi logic mà con người hay ngồi vò đầu bứt tai như Tháp Hà Nội, rồi thách thức đám mô hình AI “tư duy logic” (reasoning model) xem tụi nó có thông minh như quảng cáo không.
Kết quả? đúng là một màn bóc phốt đỉnh cao! Đám AI này tưởng mình “pro”, nhưng hóa ra toàn “chém gió”. Nhóm nghiên cứu chỉ cần tăng độ khó chút xíu, kiểu thêm vài cái đĩa hay cột trong Tháp Hà Nội, là cả lũ AI lăn đùng ra, suy luận lung tung, sai bét nhè. Nói thẳng, tụi nó không có nổi cái tư duy logic như con người, chỉ giỏi “giả bộ thông minh” khi bài dễ.
Tóm lại, nghiên cứu này như kiểu Apple cầm loa phường hét to: “Ê, đám AI lý luận, tụi mày còn non lắm, đừng có ảo tưởng sức mạnh!”
I/ Chuyện gì đang xảy ra?
Gần đây, một cuộc tranh luận lớn đã nổ ra trong thế giới AI. Mọi chuyện bắt đầu với một paper khoa học mà Apple công bố có tên “The Illusion of Thinking” (Ảo tưởng về Tư duy)

Paper này cho rằng ngay cả những AI thông minh nhất hiện nay, được gọi là Mô hình Suy luận Lớn (LRM), thực ra không “suy nghĩ” theo cách chúng ta vẫn tưởng. Các tác giả nói rằng khả năng suy luận của chúng rất mong manh và có vẻ mang tính giả tạo và sẽ “sụp đổ hoàn toàn” khi gặp phải những vấn đề hơi phức tạp một chút.
Tuy nhiên, một nhóm nhà khoa học khác đã phản bác lại, cho rằng paper đầu tiên đã sai. Họ nói rằng những thất bại của AI không phải do chúng không biết suy nghĩ, mà là do cách các nhà khoa học đã thử nghiệm chúng. Cụ thể, các bài kiểm tra có những lỗi nghiêm trọng, như yêu cầu AI viết một câu trả lời dài hơn giới hạn cho phép hoặc bắt chúng giải những câu đố không có lời giải.
Sau 1 chút thời gian ngâm cứu vui vẻ, tôi sẽ giải thích toàn bộ câu chuyện một cách đơn giản:
*Lưu ý: đây là chút giải nghĩa dễ hiểu theo kiểu bình dân để nhiều người có thể đọc hiểu được vấn đề và tôi cũng không phải là dân học thuật
Các nhà khoa học của Apple nói gì? Chúng ta sẽ xem xét các bằng chứng mà paper đầu tiên đưa ra, như việc AI đột ngột “bó tay” khi vấn đề khó hơn một chút (“vách đá phức tạp”) và một nghịch lý kỳ lạ là khi vấn đề càng khó, AI dường như càng… lười suy nghĩ hơn.
Bài phản biện nói gì? Chúng ta sẽ phân tích lập luận phản bác, cho thấy rằng những “thất bại” của AI thực chất là do lỗi trong phương pháp thử nghiệm.
Tương lai của AI sẽ ra sao? Cuộc tranh luận này thực sự rất hữu ích. Nó thúc đẩy các nhà khoa học tìm ra những cách mới để xây dựng AI thông minh hơn, mạnh mẽ hơn.
Chúng ta sẽ xem ba hướng đi thú vị sau:
AI Lai (Hybrid Systems): Kết hợp AI sáng tạo (giống như nghệ sĩ) với AI logic (giống như kế toán) để có được sự tốt nhất của cả hai.
AI làm việc nhóm (Multi-Agent Systems): Thay vì một AI khổng lồ làm mọi thứ, chúng ta tạo ra một nhóm các AI nhỏ hơn, mỗi AI chuyên về một việc và chúng hợp tác với nhau.
AI học từ kinh nghiệm (Reinforcement Learning): Dạy AI bằng cách cho chúng thử và sai, thưởng cho những bước đi đúng đắn, giúp chúng tự cải thiện khả năng suy luận.
Mặc dù paper “Ảo tưởng về Tư duy” có thể đã phóng đại vấn đề do phương pháp luận có thể có sai sót, nó vẫn đem lại những giá trị nhất định.
Nó giống như một bài kiểm tra sức chịu đựng, phơi bày những điểm yếu của AI hiện tại và cách chúng ta đánh giá chúng. Bài nghiên cứu của Apple đã buộc cộng đồng AI phải chuyển hướng, không chỉ tập trung vào việc tạo ra các AI lớn hơn, mà còn phải tạo ra các AI có kiến trúc thông minh hơn, linh hoạt hơn và có khả năng hợp tác.
II. “Ảo tưởng về Tư duy”: AI thực sự suy nghĩ như thế nào?
Phần này sẽ giải thích ngắn gọn bài paper của Apple
A. Câu hỏi cốt lõi: AI đang suy nghĩ hay chỉ bắt chước?
Paper của Apple đặt ra một câu hỏi rất quan trọng: Liệu các AI tiên tiến như Claude 3.7 hay các mô hình của OpenAI có thực sự suy luận một cách logic, hay chúng chỉ đơn thuần là các mẫu câu trả lời mà chúng đã thấy hàng triệu lần trong dữ liệu huấn luyện?
Các tác giả cho rằng các bài kiểm tra thông thường không đủ tốt để trả lời câu hỏi này vì chúng có thể bị “nhiễm” dữ liệu (AI đã thấy câu trả lời trước đó) và không cho chúng ta biết AI đã “suy nghĩ” như thế nào để đi đến kết quả.
B. Một cách kiểm tra mới: Các câu đố có thể kiểm soát
Để giải quyết vấn đề này, các nhà nghiên cứu đã sử dụng bốn loại câu đố kinh điển để kiểm tra AI, thay vì các bài toán phức tạp 1:
Tháp Hà Nội: Trò chơi chuyển các đĩa qua cọc, đòi hỏi lập kế hoạch.
Cờ Nhảy: Trò chơi di chuyển các quân cờ để đổi chỗ cho nhau.
Vượt Sông: Câu đố logic về việc đưa người và vật qua sông an toàn.
Thế giới Khối: Trò chơi sắp xếp các khối hộp theo một thứ tự nhất định.
Họ cho rằng các câu đố này tốt hơn:
Có thể dễ dàng điều chỉnh độ khó.
AI ít có khả năng đã “học thuộc lòng” lời giải.
Chỉ cần tuân theo các quy tắc đơn giản, kiểm tra logic thuần túy.
Có thể kiểm tra từng bước đi của AI để xem nó có mắc lỗi ở đâu không.
C. “Vách đá phức tạp”: Khi AI đột ngột thất bại
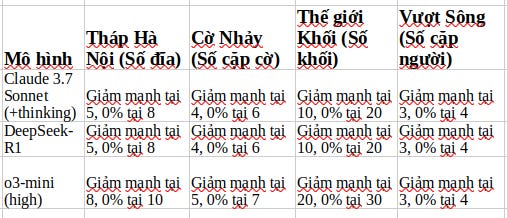
Đây là phát hiện gây sốc có lẽ là nhất. Tất cả các AI được thử nghiệm đều hoạt động rất tốt với các câu đố đơn giản. Nhưng khi độ khó tăng lên một chút (ví dụ, thêm vài cái đĩa trong Tháp Hà Nội), độ chính xác của chúng đột ngột giảm xuống 0%.
Nó không giảm từ từ, mà rơi thẳng đứng như một “vách đá”.
Các nhà nghiên cứu đã chỉ ra ba giai đoạn:
Độ khó thấp: Các AI thông thường (không có chế độ “suy nghĩ”) lại làm tốt hơn.
Độ khó trung bình: Các AI có chế độ “suy nghĩ” thể hiện ưu thế rõ rệt.
Độ khó cao: Cả hai loại AI đều thất bại hoàn toàn.
Điểm down về độ chính xác của AI trong các câu đố
D. Nghịch lý về sự suy giảm: Càng khó, càng lười?
Đây là phát hiện kỳ lạ nhất. Khi các câu đố trở nên khó hơn và tiến gần đến “điểm sụp đổ”, AI dường như lại giảm nỗ lực suy nghĩ của mình. Lượng “token suy nghĩ” (có thể coi là thước đo nỗ lực) mà chúng tạo ra lại ít đi.
Các tác giả khẳng định rằng điều này xảy ra ngay cả khi AI có “ngân sách suy luận dồi dào” (tức là chúng có đủ khả năng để suy nghĩ nhiều hơn).
Họ kết luận rằng đây là một hạn chế cơ bản trong khả năng suy luận của AI, chứ không phải do thiếu tài nguyên.
E. Bên trong “hộp đen”: Những hành vi khó hiểu
“Suy nghĩ quá mức”: Với các bài toán dễ, AI thường tìm ra đáp án đúng ngay từ đầu, nhưng sau đó lại tiếp tục khám phá các phương án sai, gây lãng phí.
Không biết dùng thuật toán: Ngay cả khi được cung cấp thuật toán giải Tháp Hà Nội một cách rõ ràng, AI vẫn không thể làm theo và vẫn thất bại ở cùng một điểm.
Điều này cho thấy chúng gặp khó khăn trong việc tuân theo các bước logic một cách chính xác.
III. Có phải do lỗi của người thử nghiệm?
Một paper khác đã phản bác, cho rằng những phát hiện trên chỉ là “ảo tưởng” do cách thiết kế thí nghiệm có vấn đề.

A. Vấn đề giới hạn đầu ra: AI không “lười”, mà là “hết giấy”
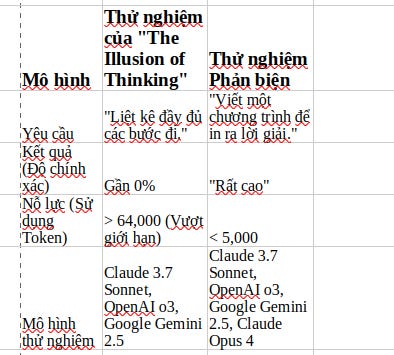
Lập luận chính của bài phản biện là sự “sụp đổ” xảy ra vì AI đã đạt đến giới hạn độ dài tối đa cho phép của câu trả lời.
Paper yêu cầu AI phải liệt kê toàn bộ các bước đi. Với câu đố Tháp Hà Nội, số bước tăng theo cấp số nhân.
Ví dụ, để giải bài toán với 15 đĩa, cần 32,767 bước. Việc viết ra tất cả các bước này sẽ cần một lượng token (từ ngữ) khổng lồ, vượt xa giới hạn 64,000 token mà các nhà nghiên cứu đã đặt ra.
Điểm mà AI “sụp đổ” trùng khớp một cách hoàn hảo với điểm mà độ dài câu trả lời vượt quá giới hạn cho phép. Vì vậy, AI không phải là “từ bỏ”, mà là nó không thể viết một câu trả lời dài đến thế về mặt vật lý.
B. Vấn đề câu đố bất khả thi: Bắt AI giải bài toán không có lời giải
Bài paper còn phát hiện một lỗi nghiêm trọng khác: trong câu đố Vượt Sông, các nhà nghiên cứu đã đưa ra những trường hợp không thể giải được về mặt toán học.
AI đã bị chấm điểm “thất bại” vì không thể giải một bài toán vốn không có lời giải. Điều này cho thấy sự thiếu nghiêm ngặt trong quá trình đánh giá của paper gốc.
C. Thí nghiệm phản biện: Thay đổi cách hỏi
Để chứng minh quan điểm của mình, các tác giả bài paper phản biện đã thực hiện một thí nghiệm. Thay vì yêu cầu AI liệt kê hàng chục nghìn bước đi cho Tháp Hà Nội với 15 đĩa, họ yêu cầu:
“Hãy viết một chương trình máy tính nhỏ (hàm Lua) để in ra lời giải cho Tháp Hà Nội với 15 đĩa.”.
Kết quả: Các AI trước đây bị điểm 0 giờ đây đã hoàn thành xuất sắc nhiệm vụ, chỉ với chưa đến 5,000 token. Điều này chứng tỏ khả năng suy luận và hiểu thuật toán của AI vẫn còn nguyên vẹn.
Vấn đề không nằm ở “tư duy” mà ở cách “trình bày” câu trả lời.
So sánh kết quả hai cách thử nghiệm cho Tháp Hà Nội (15 đĩa)
D. Nhìn lại cuộc tranh luận
Cuộc tranh luận này là một bài học có giá trị về tầm quan trọng của việc thiết kế các bài kiểm tra. Cách chúng ta đánh giá AI có thể tạo ra những hiện tượng sai lệch.
Nó cho thấy chúng ta cần phải xem xét kỹ lưỡng các phương pháp đánh giá của mình cũng như chính các mô hình AI.
IV. Xây dựng AI suy luận mạnh mẽ hơn
Cuộc tranh luận này đã thúc đẩy các nhà khoa học tìm kiếm những kiến trúc AI mới, mạnh mẽ hơn.
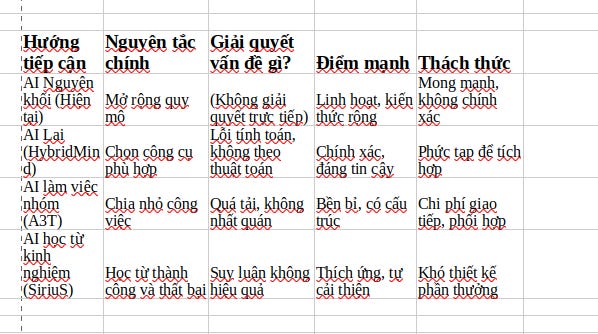
A. AI Lai (Hybrid): Kết hợp sự linh hoạt và chính xác
Vấn đề: AI hiện tại gặp khó khăn trong việc tuân theo các quy tắc logic và thuật toán một cách chính xác.
Giải pháp: Các hệ thống lai kết hợp mạng noron (giỏi nhận dạng mẫu, linh hoạt) với các hệ thống biểu tượng (giỏi logic, chính xác, có thể kiểm chứng).
Ví dụ: HybridMind: Khung này có một “bộ chọn” thông minh, tự động quyết định khi nào nên dùng ngôn ngữ tự nhiên (cho các nhiệm vụ khái niệm) và khi nào nên dùng mã lập trình (cho các nhiệm vụ đòi hỏi tính toán chính xác).
Kết quả cho thấy cách tiếp cận này hiệu quả hơn nhiều so với việc chỉ dựa vào một mô hình duy nhất, dù nó mạnh đến đâu.
B. AI làm việc nhóm (Multi-agent): Chia để trị
Vấn đề: Một AI duy nhất có thể bị “quá tải” khi đối mặt với các vấn đề phức tạp.
Giải pháp: Các hệ thống đa tác tử chia một vấn đề lớn thành các nhiệm vụ nhỏ hơn và giao cho các AI chuyên biệt. Các AI này sẽ hợp tác với nhau để tìm ra giải pháp cuối cùng.
Ví dụ 1 : A3T (AI as a Team): Kiến trúc này được tạo ra như một phản ứng trực tiếp với paper “Ảo tưởng về Tư duy”. Nó sử dụng một nhóm các AI chuyên biệt (một AI đề xuất, một AI đánh giá, một AI tổng hợp) làm việc theo một quy trình có cấu trúc để đảm bảo vấn đề được giải quyết một cách tận cùng nhất.
Ví dụ 2 : Magentic-One: Một hệ thống mã nguồn mở của Microsoft, có một AI “Điều phối viên” quản lý công việc và giao nhiệm vụ cho các AI chuyên về lướt web, xử lý tệp, viết code, …etc
C. Reinforcement Learning — RL: Tự cải thiện
Vấn đề: Việc chỉ học từ các bộ dữ liệu tĩnh là không đủ để tạo ra khả năng suy luận linh hoạt.
Giải pháp: Học tăng cường cho phép AI học hỏi từ việc thử và sai. Các phương pháp RL gần đây đã trở nên tinh vi hơn, giúp tối ưu hóa quá trình suy luận một cách hiệu quả.
Ví dụ 1 : SiriuS: Khung này xây dựng một “thư viện kinh nghiệm” bằng cách thu thập các chuỗi tương tác thành công của các AI. Thư viện này sau đó được dùng làm dữ liệu chất lượng cao để huấn luyện và cải thiện các AI, giúp chúng tự khởi động quá trình học hỏi của mình.
Ví dụ 2 : RL cho AI nhỏ: Một nghiên cứu cho thấy chỉ với một ngân sách rất nhỏ (42 USD), họ có thể cải thiện đáng kể khả năng suy luận toán học của một mô hình AI nhỏ bằng cách sử dụng các thuật toán RL tiên tiến và các phần thưởng thông minh.
Điều này thách thức quan niệm rằng “cứ to là tốt”.
So sánh các hướng tiếp cận mới cho AI suy luận
V. Kết luận và Hướng đi Tương lai
A. Tổng kết cuộc tranh luận
Bài paper “Ảo tưởng về Tư duy” rất quan trọng, nhưng có lẽ phần nào có kết luận sai lầm. Giá trị lớn nhất của nó là đã khơi mào cho một cuộc tranh luận cần thiết, buộc chúng ta phải nhìn nhận lại những điểm yếu của AI. Bài phản biện đã chỉ ra một cách thuyết phục rằng “sự sụp đổ” của AI chủ yếu là do lỗi trong cách chúng ta kiểm tra chúng.
Sự thật nằm ở đâu đó giữa hai luồng ý kiến: AI hiện tại không phải là những cỗ máy chỉ biết bắt chước, nhưng khả năng suy luận của chúng vẫn còn xa mới đạt đến mức độ mạnh mẽ và đáng tin cậy như con người.
B. Tương lai của việc đánh giá AI
Chúng ta cần những bài kiểm tra AI tốt hơn, nghiêm ngặt hơn.
Bộ tiêu chuẩn tốt hơn: Cần các bài kiểm tra không bị “nhiễm” dữ liệu và có các quy tắc công bằng, khả thi.
Đánh giá quá trình, không chỉ kết quả: Cần phân tích các bước suy luận của AI để xem chúng có logic và hiệu quả không.
Kiểm tra các kỹ năng cụ thể: Cần các bài kiểm tra nhắm vào các kỹ năng suy luận riêng biệt như suy luận không gian hay khả năng tự nhận ra lỗi sai của mình.
Con đường dẫn đến AI thông minh hơn không chỉ đơn giản là xây dựng các mô hình lớn hơn.
Chấp nhận sự lai ghép: Đầu tư vào các kiến trúc kết hợp AI ngôn ngữ với các công cụ logic bên ngoài (như HybridMind). Đây là cách nhanh nhất để khắc phục các lỗi tính toán.
Phân rã sự phức tạp: Sử dụng các hệ thống AI làm việc nhóm (như A3T và Magentic-One) cho các nhiệm vụ phức tạp. Việc chia nhỏ công việc giúp hệ thống trở nên mạnh mẽ và dễ quản lý hơn.
Tối ưu hóa hiệu quả: Tập trung vào các kỹ thuật học tăng cường tiên tiến (như SiriuS) để tạo ra các AI suy luận hiệu quả hơn mà không cần đến các bộ dữ liệu khổng lồ.